what
研究了一下 golang 相关的文档,写下这篇 golang 入门日记,包含 golang 基础教程,这是 golang 语言初探第二篇。
- golang语言初探一
- golang语言初探二
- golang语言初探三
why
周末的时候研究了一下 golang 相关的文档,根据自己的工作经验,我觉得这门语言在未来一定会大放异彩,其实现在也比较热门了。主要有以下几个特点:
- 语法简单,golang 的关键字才 25 个,入门也非常简单
- 天然支持高并发,适用于大型微服务应用
- 跨平台,可编译出支持各大主流平台的应用,且毫无依赖
经过对 golang 的这些了解,顿时感觉有点兴趣了,在这里记录一些入门的资料。
how
高级数据类型
数组类型
个数组(Array)就是一个可以容纳若干类型相同的元素的容器。这个容器的大小(即数组的长度)是固定的,且是体现在数组的类型字面量之中的。比如,我们声明了一个数组类型:
type MyNumbers [3]int注:类型声明语句由关键字type、类型名称和类型字面量组成。
所谓类型字面量,就是用于表示某个类型的字面表示(或称标记方法)。相对的,用于表示某个类型的值的字面表示可被称为值字面量,或简称为字面量。比如之前提到过的3.7E-2就可被称为浮点数字面量。 类型字面量[3]int由两部分组成。第一部分是由方括号包裹的数组长度,即[3]。这也意味着,一个数组的长度是该数组的类型的组成部分,是固定不变的。该类型字面量的第二个组成部分是int。它代表了该数组可以容纳的元素的类型。说到这里,上面这条类型声明语句实际上是为数组类型[3]int声明了一个别名类型。这使得我们可以把 MyNumbers 当做数组类型[3]int来使用。
我们表示这样一个数组类型的值的时候,应该把该类型的类型字面量写在最左边,然后用花括号包裹该值包含的若干元素。各元素之间以(英文半角)逗号分隔,即:
[3]int{1, 2, 3}现在,我们把这个数组字面量赋给一个名为 numbers 的变量:
var numbers = [3]int{1, 2, 3}注:这是一条变量声明语句。它在声明变量的同时为该变量赋值。
另一种便捷方法是,在其中的类型字面量中省略代表其长度的数字,像这样:
var numbers = [...]int{1, 2, 3}这样就可以免去我们为填入那个数字而数出元素个数的工作了。
接下来,我们可以很方便地使用索引表达式来访问该变量的值中的任何一个元素,例如:
numbers[0] // 会得到第一个元素
numbers[1] // 会得到第二个元素
numbers[2] // 会得到第三个元素注:索引表达式由字符串、数组、切片或字典类型的值(或者代表此类值的变量或常量)和由方括号包裹的索引值组成。在这里,索引值的有效范围是[0, 3)。也就是说,对于数组来说,索引值既不能小于0也不能大于或等于数组值的长度。另外要注意,索引值的最小有效值总是 0,而不是 1 。
相对的,如果我们想修改数组值中的某一个元素值,那么可以使用赋值语句直接达到目的。例如,我们要修改 numbers 中的第二个元素的话,如此即可:
numbers[1] = 4虽然数组的长度已经体现在了它的类型字面量,但是我们在很多时候仍然需要明确的获得它,像这样:
var length = len(numbers)注:len是Go语言的内建函数的名称。该函数用于获取字符串、数组、切片、字典或通道类型的值的长度。我们可以在Go语言源码文件中直接使用它。
最后,要注意,如果我们只声明一个数组类型的变量而不为它赋值,那么该变量的值将会是指定长度的、其中各元素均为元素类型的零值(或称默认值)的数组值。例如,若有这样一个变量:
var numbers2 [5]int则它的值会是
[5]int{0, 0, 0, 0, 0}切片类型
切片(Slice)与数组一样,也是可以容纳若干类型相同的元素的容器。与数组不同的是,无法通过切片类型来确定其值的长度。每个切片值都会将数组作为其底层数据结构。我们也把这样的数组称为切片的底层数组。表示切片类型的字面量如:
[]int
// 或
[]string可以看到,它们与数组的类型字面量的唯一不同是不包含代表其长度的信息。因此,不同长度的切片值是有可能属于同一个类型的。相对的,不同长度的数组值必定属于不同类型。对一个切片类型的声明可以这样:
type MySlice []int这时,类型 MySlice 即为切片类型 []int 的一个别名类型。除此之外,对切片值的表示也与数组值也极其相似,如:
[]int{1, 2, 3}这样的字面量与数组(值)的字面量的区别也只在于最左侧的类型字面量。
操作数组值的方法也同样适用于切片值。不过,还有一种操作数组值的方法,这种操作的名称就叫“切片”。实施切片操作的方式就是切片表达式。举例如下:
var numbers3 = [5]int{1, 2, 3, 4, 5}
var slice1 = numbers3[1:4]请注意第二条赋值语句中在“ = ”右边那个部分。切片表达式一般由字符串、数组或切片的值以及由方括号包裹且由英文冒号“:”分隔的两个正整数组成。这两个正整数分别表示元素下界索引和元素上界索引。在本例中,切片表达式numbers3[1:4]的求值结果为[]int{2, 3, 4}。可见,切片表达式的求值结果相当于以元素下界索引和元素上界索引作为依据从被操作对象上“切下”而形成的新值。注意,被“切下”的部分不包含元素上界索引指向的元素。另外,切片表达式的求值结果会是切片类型的,且其元素类型与被“切片”的值的元素类型一致。实际上,slice1 这个切片值的底层数组正是 numbers3 的值。
实际上,我们也可以在一个切片值上实施切片操作。操作的方式与上述无异。请看下面这个例子:
var slice2 = slice1[1:3]据此,slice2 的值为[]int{3, 4}。注意,作为切片表达式求值结果的切片值的长度总是为元素上界索引与元素下界索引的差值。
除了长度,切片值以及数组值还有另外一个属性——容量。数组值的容量总是等于其长度。而切片值的容量则往往与其长度不同。
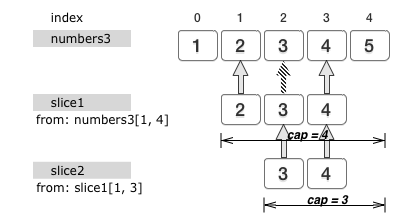
如图所示,一个切片值的容量即为它的第一个元素值在其底层数组中的索引值与该数组长度的差值的绝对值。为了获取数组、切片或通道类型的值的容量,我们可以使用内建函数cap,如:
var capacity2 int = cap(slice2)最后,要注意,切片类型属于引用类型。它的零值即为 nil ,即空值。如果我们只声明一个切片类型的变量而不为它赋值,那么该变量的值将会是 nil 。例如,若有这样一个变量:
var slice3 []int则它的值会是 nil 。
在有些时候,我们还可以在方括号中放入第三个正整数,如下所示:
numbers3[1:4:4]这第三个正整数被称为容量上界索引。它的意义在于可以把作为结果的切片值的容量设置得更小。换句话说,它可以限制我们通过这个切片值对其底层数组中的更多元素的访问。下面举个例子。 numbers3 和 slice1 ,针对它们的赋值语句是这样的:
var numbers3 = [5]int{1, 2, 3, 4, 5}
var slice1 = numbers3[1:4]这时,变量 slice1 的值是 []int{2, 3, 4} 。但是我们可以通过如下操作将其长度延展得与其容量相同:
slice1 = slice1[:cap(slice1)]
通过此操作,变量 slice1 的值变为了 []int{2, 3, 4, 5} ,且其长度和容量均为 4 。现在,numbers3 的值中的索引值在 [1,5) 范围内的元素都被体现在了 slice1 的值中。这是以 numbers3 的值是 slice1 的值的底层数组为前提的。这意味着,我们可以轻而易举地通过切片值访问其底层数组中对应索引值更大的更多元素。如果我们编写的函数返回了这样一个切片值,那么得到它的程序很可能会通过这种技巧访问到本不应该暴露给它的元素。这是确确实实是一个安全隐患。
如果我们在切片表达式中加入了第三个索引(即容量上界索引),如:
var slice1 = numbers3[1:4:4]那么在这之后,无论我们怎样做都无法通过 slice1 访问到 numbers3 的值中的第五个元素。因为这超出了我们刚刚设定的 slice1 的容量。如果我们指定的元素上界索引或容量上界索引超出了被操作对象的容量,那么就会引发一个运行时恐慌(程序异常的一种),而不会有求值结果返回。因此,这是一个有力的访问控制手段。
虽然切片值在上述方面受到了其容量的限制,但是我们却可以通过另外一种手段对其进行不受任何限制地扩展。这需要使用到内建函数append。append会对切片值进行扩展并返回一个新的切片值。使用方法如下:
slice1 = append(slice1, 6, 7)通过上述操作,slice1的值变为了[]int{2, 3, 4, 6, 7}。注意,一旦扩展操作超出了被操作的切片值的容量,那么该切片的底层数组就会被自动更换。这也使得通过设定容量上界索引来对其底层数组进行访问控制的方法更加严谨了。
我们要介绍的最后一种操作切片值的方法是“复制”。该操作的实施方法是调用 copy 函数。该函数接受两个类型相同的切片值作为参数,并会把第二个参数值中的元素复制到第一个参数值中的相应位置(索引值相同)上。这里有两点需要注意:
- 这种复制遵循最小复制原则,即:被复制的元素的个数总是等于长度较短的那个参数值的长度。
- 与 append 函数不同, copy 函数会直接对其第一个参数值进行修改。
举例如下:
var slice4 = []int{0, 0, 0, 0, 0, 0, 0}
copy(slice4, slice1)通过上述复制操作, slice4 会变为 []int{2, 3, 4, 6, 7, 0, 0} 。
字典类型
Go语言的字典( Map )类型其实是哈希表( Hash Table )的一个实现。字典用于存储键-元素对(更通俗的说法是键-值对)的无序集合。
注意,同一个字典中的每个键都是唯一的。如果我们在向字典中放入一个键值对的时候其中已经有相同的键的话,那么与此键关联的那个值会被新值替换。
字典类型的字面量是 map[K]T 其中,“ K ”意为键的类型,而“ T ”则代表元素(或称值)的类型。如果我们要描述一个键类型为 int 、值类型为 string 的字典类型的话,应该这样写: map[int]string
注意,字典的键类型必须是可比较的,否则会引起错误。也就是说,它不能是切片、字典或函数类型。
字典值的字面量表示法实际上与数组和切片的字面量表示法很相似。首先,最左边仍然是类型字面量,右边紧挨着由花括号包裹且有英文逗号分隔的键值对。每个键值对的键和值之间由英文冒号分隔。以字典类型map[int]string为例,它的值的字面量可以是这样的:
map[int]string{1: "a", 2: "b", 3: "c"}我们可以把这个值赋给一个变量:
mm := map[int]string{1: "a", 2: "b", 3: "c"}然后运用索引表达式取出字典中的值,就像这样:
b := mm[2]注意,在这里,我们放入方括号中的不再是索引值(实际上,字典中的键值对也没有索引),而是与我们要取出的值对应的那个键。在上例中变量b的值必是字符串" b "。当然,也可以利用索引表达式来赋值,比如这样:
mm[2] = b + "2"这使得字典 mm 中与键 2 对应的值变为了" b2 "。现在我们再来向 mm 添加一个键值对:mm[4] = "" 之后,在从中取出与 4 和 5 对应的值:
d := mm[4]
e := mm[5]此时,变量 d 和 e 的值都会是多少呢?答案是都为"",即空字符串。对于变量 d 来说,由于在字典 mm 中与 4 对应的值就是"",所以索引表达式 mm[4] 的求值结果必为""。这理所应当。但是 mm[5] 的求值结果为什么也是空字符串呢?原因是,在 Go 语言中有这样一项规定,即:对于字典值来说,如果其中不存在索引表达式欲取出的键值对,那么就以它的值类型的空值(或称默认值)作为该索引表达式的求值结果。由于字符串类型的空值为"",所以 mm[5] 的求值结果即为""。
在不知道 mm 的确切值的情况下,我们无法得知 mm[5] 的求值结果意味着什么?它意味着 5 对应的值就是一个空字符串?还是说 mm 中根本就没有键为 5 的键值对?这无所判别。为了解决这个问题, Go 语言为我们提供了另外一个写法,即:
e, ok := mm[5]针对字典的索引表达式可以有两个求值结果。第二个求值结果是 bool 类型的。它用于表明字典值中是否存在指定的键值对。在上例中,变量 ok 必为 false 。因为 mm 中不存在以 5 为键的键值对。
从字典中删除键值对的方法非常简单,仅仅是调用内建函数 delete 而已,就像这样:
delete(mm, 4)无论 mm 中是否存在以 4 为键的键值对, delete 都会“无声”地执行完毕。我们用“有则删除,无则不做”可以很好地概括它的行为。
最后,与切片类型相同,字典类型属于引用类型。它的零值即为 nil 。
通道类型
通道( Channel )是 Go 语言中一种非常独特的数据结构。它可用于在不同 Goroutine 之间传递类型化的数据,并且是并发安全的。相比之下,我们之前介绍的那些数据类型都不是并发安全的。这一点需要特别注意。
Goroutine(也称为 Go 程序)可以被看做是承载可被并发执行的代码块的载体。它们由 Go 语言的运行时系统调度,并依托操作系统线程(又称内核线程)来并发地执行其中的代码块。
通道类型的表示方法很简单,仅由chan T两部分组成。
在这个类型字面量中,左边是代表通道类型的关键字 chan ,而右边则是一个可变的部分,即代表该通道类型允许传递的数据的类型(或称通道的元素类型)。
与其它的数据类型不同,我们无法表示一个通道类型的值。因此,我们也无法用字面量来为通道类型的变量赋值。我们只能通过调用内建函数 make 来达到目的。 make 函数可接受两个参数。第一个参数是代表了将被初始化的值的类型的字面量(比如 chan int ),而第二个参数则是值的长度。例如,若我们想要初始化一个长度为 5 且元素类型为 int 的通道值,则需要这样写:
make(chan int, 5)实际上 make 函数也可以被用来初始化切片类型或字典类型的值。
确切地说,通道值的长度应该被称为其缓存的尺寸。换句话说,它代表着通道值中可以暂存的数据的个数。注意,暂存在通道值中的数据是先进先出的。
下面,我们声明一个通道类型的变量,并为其赋值:
ch1 := make(chan string, 5)这样一来,我们就可以使用接收操作符 <- 向通道值发送数据了。当然,也可以使用它从通道值接收数据。例如,如果我们要向通道 ch1 发送字符串 “value1” ,那么应该这样做:
ch1 <- "value1"另一方面,我们若想从ch1那里接收字符串,则要这样:
value := <- ch1与针对字典值的索引表达式一样,针对通道值的接收操作也可以有第二个结果值。
value, ok := <- ch1这样做的目的同样是为了消除与零值有关的歧义。这里的变量 ok 的值同样是 bool 类型的。它代表了通道值的状态, true 代表通道值有效,而 false 则代表通道值已无效(或称已关闭)。更深层次的原因是,如果在接收操作进行之前或过程中通道值被关闭了,则接收操作会立即结束并返回一个该通道值的元素类型的零值。按照上面的第一种写法,我们无从判断接收到零值的原因是什么。不过,有了第二个结果值之后,这种判断就好做了。
说到关闭通道值,我们可以通过调用内建函数 close 来达到目的,就像这样:
close(ch1)注意,对通道值的重复关闭会引发运行时恐慌。这会使程序崩溃。所以一定要避免这种情况的发生。另外,在通道值有效的前提下,针对它的发送操作会在通道值已满(其中缓存的数据的个数已等于它的长度)时被阻塞。而向一个已被关闭的通道值发送数据会引发运行时恐慌。另一方面,针对有效通道值的接收操作会在它已空(其中没有缓存任何数据)时被阻塞。除此之外,还有几条与通道的发送和接收操作有关的规则。不过在这里我们记住上面这三条就可以了。
通道有带缓冲和非缓冲之分。我们已经说过,缓冲通道中可以缓存 N 个数据。我们在初始化一个通道值的时候必须指定这个 N 。相对的,非缓冲通道不会缓存任何数据。发送方在向通道值发送数据的时候会立即被阻塞,直到有某一个接收方已从该通道值中接收了这条数据。非缓冲的通道值的初始化方法如下:
make(chan int, 0)注意,在这里,给予 make 函数的第二个参数值是 0 。
除了上述分类方法,我们还可以以数据在通道中的传输方向为依据来划分通道。默认情况下,通道都是双向的,即双向通道。如果数据只能在通道中单向传输,那么该通道就被称作单向通道。我们在初始化一个通道值的时候不能指定它为单向。但是,在编写类型声明的时候,我们却是可以这样做的。例如:
type Receiver <-chan int类型 Receiver 代表了一个只可从中接收数据的单向通道类型。这样的通道也被称为接收通道。在关键字 chan 左边的接收操作符 <- 形象地表示出了数据的流向。相对应的,如果我们想声明一个发送通道类型,那么应该这样:
type Sender chan<- int这次 <- 被放在了 chan 的右边,并且“箭头”直指“通道”。想必不用多说你也能明白了。我们可以把一个双向通道值赋予上述类型的变量,就像这样:
var myChannel = make(chan int, 3)
var sender Sender = myChannel
var receiver Receiver = myChannel但是,反之则是不行的。像下面这样的代码是通不过编译的:
var myChannel1 chan int = sender单向通道的主要作用是约束程序对通道值的使用方式。比如,我们调用一个函数时给予它一个发送通道作为参数,以此来约束它只能向该通道发送数据。又比如,一个函数将一个接收通道作为结果返回,以此来约束调用该函数的代码只能从这个通道中接收数据。这属于 API 设计的范畴。
最后,与切片和字典类型相同,通道类型属于引用类型。它的零值即为 nil 。
函数
在 Go 语言中,函数是一等( first-class )类型。这意味着,我们可以把函数作为值来传递和使用。函数代表着这样一个过程:它接受若干输入(参数),并经过一些步骤(语句)的执行之后再返回输出(结果)。特别的是, Go 语言中的函数可以返回多个结果。
函数类型的字面量由关键字 func 、由圆括号包裹参数声明列表、空格以及可以由圆括号包裹的结果声明列表组成。其中,参数声明列表中的单个参数声明之间是由英文逗号分隔的。每个参数声明由参数名称、空格和参数类型组成。参数声明列表中的参数名称是可以被统一省略的。结果声明列表的编写方式与此相同。结果声明列表中的结果名称也是可以被统一省略的。并且,在只有一个无名称的结果声明时还可以省略括号。示例如下:
func(input1 string ,input2 string) string这一类型字面量表示了一个接受两个字符串类型的参数且会返回一个字符串类型的结果的函数。如果我们在它的左边加入 type 关键字和一个标识符作为名称的话,那就变成了一个函数类型声明,就像这样:
type MyFunc func(input1 string ,input2 string) string函数值(或简称函数)的写法与此不完全相同。编写函数的时候需要先写关键字 func 和函数名称,后跟参数声明列表和结果声明列表,最后是由花括号包裹的语句列表。例如:
func myFunc(part1 string, part2 string) (result string) {
result = part1 + part2
return
}我们在这里用到了一个小技巧:如果结果声明是带名称的,那么它就相当于一个已被声明但未被显式赋值的变量。我们可以为它赋值且在 return 语句中省略掉需要返回的结果值。显然,该函数还有一种更常规的写法:
func myFunc(part1 string, part2 string) string {
return part1 + part2
}注意,函数 myFunc 是函数类型 MyFunc 的一个实现。实际上,只要一个函数的参数声明列表和结果声明列表中的数据类型的顺序和名称与某一个函数类型完全一致,前者就是后者的一个实现。请大家回顾上面的示例并深刻理解这句话。
我们可以声明一个函数类型的变量,如:
var splice func(string, string) string // 等价于 var splice MyFunc然后把函数myFunc赋给它:
splice = myFunc如此一来,我们就可以在这个变量之上实施调用动作了:
splice("1", "2")实际上,这是一个调用表达式。它由代表函数的标识符(这里是 splice )以及代表调用动作的、由圆括号包裹的参数值列表组成。
如果你觉得上面对 splice 变量声明和赋值有些啰嗦,那么可以这样来简化它:
var splice = func(part1 string, part2 string) string {
return part1 + part2
}在这个示例中,我们直接使用了一个匿名函数来初始化 splice 变量。顾名思义,匿名函数就是不带名称的函数值。匿名函数直接由函数类型字面量和由花括号包裹的语句列表组成。
注意,这里的函数类型字面量中的参数名称是不能被忽略的。
其实,我们还可以进一步简化——索性省去 splice 变量。既然我们可以在代表函数的变量上实施调用表达式,那么在匿名函数上肯定也是可行的。因为它们的本质是相同的。后者的示例如下:
var result = func(part1 string, part2 string) string {
return part1 + part2
}("1", "2")可以看到,在这个匿名函数之后的即是代表调用动作的参数值列表。注意,这里的 result 变量的类型不是函数类型,而与后面的匿名函数的结果类型是相同的。
最后,函数类型的零值是 nil 。这意味着,一个未被显式赋值的、函数类型的变量的值必为 nil 。
结构体和方法
Go 语言的结构体类型( Struct )比函数类型更加灵活。它可以封装属性和操作。前者即是结构体类型中的字段,而后者则是结构体类型所拥有的方法。
结构体类型的字面量由关键字 type 、类型名称、关键字 struct ,以及由花括号包裹的若干字段声明组成。其中,每个字段声明独占一行并由字段名称(可选)和字段类型组成。示例如下:
type Person struct {
Name string
Gender string
Age uint8
}结构体类型 Person 中有三个字段,分别是 Name 、 Gender 和 Age 。我们可以用字面量创建出一个该类型的值,像这样:
Person{Name: "Robert", Gender: "Male", Age: 33}可以看到,结构体值的字面量(或简称结构体字面量)由其类型的名称和由花括号包裹的若干键值对组成。
注意,这里的键值对与字典字面量中的键值对的写法相似,但不相同。这里的键是其类型中的某个字段的名称(注意,它不是字符串字面量),而对应的值则是欲赋给该字段的那个值。另外,如果这里的键值对的顺序与其类型中的字段声明完全相同的话,我们还可以统一省略掉所有字段的名称,就像这样:
Person{"Robert", "Male", 33}当然,我们在编写某个结构体类型的值字面量时可以只对它的部分字段赋值,甚至不对它的任何字段赋值。这时,未被显式赋值的字段的值则为其类型的零值。注意,在上述两种情况下,字段的名称是不能被省略的。
与代表函数值的字面量类似,我们在编写一个结构体值的字面量时不需要先拟好其类型。这样的结构体字面量被称为匿名结构体。与匿名函数类似,我们在编写匿名结构体的时候需要先写明其类型特征(包含若干字段声明),再写出它的值初始化部分。下面,我们依照结构体类型 Person 创建一个匿名结构体:
p := struct {
Name string
Gender string
Age uint8
}{"Robert", "Male", 33}匿名结构体最大的用处就是在内部临时创建一个结构以封装数据,而不必正式为其声明相关规则。而在涉及到对外的场景中,强烈建议使用正式的结构体类型。
结构体类型可以拥有若干方法(注意,匿名结构体是不可能拥有方法的)。所谓方法,其实就是一种特殊的函数。它可以依附于某个自定义类型。方法的特殊在于它的声明包含了一个接收者声明。这里的接收者指代它所依附的那个类型。我们仍以结构体类型 Person 为例。下面是依附于它的一个名为 Grow 的方法的声明:
func (person *Person) Grow() {
person.Age++
}如上所示,在关键字 func 和名称 Grow 之间的那个圆括号及其包含的内容就是接收者声明。其中的内容由两部分组成。第一部分是代表它依附的那个类型的值的标识符。第二部分是它依附的那个类型的名称。后者表明了依附关系,而前者则使得在该方法中的代码可以使用到该类型的值(也称为当前值)。代表当前值的那个标识符可被称为接收者标识符,或简称为接收者。请看下面的示例:
p := Person{"Robert", "Male" 33}
p.Grow()我们可以直接在 Person 类型的变量 p 之上应用调用表达式来调用它的方法 Grow 。注意,此时方法 Grow 的接收者标识符 person 指代的正是变量 p 的值。这也是“当前值”这个词的由来。在 Grow 方法中,我们通过使用选择表达式选择了当前值的字段 Age ,并使其自增。因此,在语句 p.Grow() 被执行之后, p 所代表的那个人就又年长了一岁( p 的 Age 字段的值已变为 34 )。
需要注意的是,在 Grow 方法的接收者声明中的那个类型是 *Person ,而不是 Person 。实际上,前者是后者的指针类型。这也使得 person 指代的是 p 的指针,而不是它本身。
说到这里,熟悉面向对象编程的同学可能已经意识到,包含若干字段和方法的结构体类型就相当于一个把属性和操作封装在一起的对象。不过要注意,与对象不同的是,结构体类型(以及任何类型)之间都不可能存在继承关系。实际上,在 Go 语言中并没有继承的概念。
最后,结构体类型属于值类型。它的零值并不是 nil ,而是其中字段的值均为相应类型的零值的值。举个例子,结构体类型 Person 的零值若用字面量来表示的话则为 Person{} 。
接口
在 Go 语言中,一个接口类型总是代表着某一种类型(即所有实现它的类型)的行为。一个接口类型的声明通常会包含关键字 type 、类型名称、关键字 interface 以及由花括号包裹的若干方法声明。示例如下:
type Animal interface {
Grow()
Move(string) string
}注意,接口类型中的方法声明是普通的方法声明的简化形式。它们只包括方法名称、参数声明列表和结果声明列表。其中的参数的名称和结果的名称都可以被省略。不过,出于文档化的目的,我还是建议大家在这里写上它们。因此, Move 方法的声明至少应该是这样的:
Move(new string) (old string)如果一个数据类型所拥有的方法集合中包含了某一个接口类型中的所有方法声明的实现,那么就可以说这个数据类型实现了那个接口类型。所谓实现一个接口中的方法是指,具有与该方法相同的声明并且添加了实现部分(由花括号包裹的若干条语句)。相同的方法声明意味着完全一致的名称、参数类型列表和结果类型列表。其中,参数类型列表即为参数声明列表中除去参数名称的部分。一致的参数类型列表意味着其长度以及顺序的完全相同。对于结果类型列表也是如此。
*Person 类型(注意,不是Person类型)拥有一个 Move 方法。该方法会是Animal接口的 Move 方法的一个实现。再加上我们在之前为它编写的那个 Grow 方法,*Person类型就可以被看做是 Animal 接口的一个实现类型了。
你可能已经意识到,我们无需在一个数据类型中声明它实现了哪个接口。只要满足了“方法集合为其超集”的条件,就建立了“实现”关系。这是典型的无侵入式的接口实现方法。
好了,现在我们已经认为 *Person 类型实现了 Animal 接口。但是 Go 语言编译器是否也这样认为呢?这显然需要一种显式的判定方法。在 Go 语言中,这种判定可以用类型断言来实现。不过,在这里,我们是不能在一个非接口类型的值上应用类型断言来判定它是否属于某一个接口类型的。我们必须先把前者转换成空接口类型的值。这又涉及到了 Go 语言的类型转换。
Go 语言的类型转换规则定义了是否能够以及怎样可以把一个类型的值转换另一个类型的值。另一方面,所谓空接口类型即是不包含任何方法声明的接口类型,用 interface{} 表示,常简称为空接口。正因为空接口的定义,Go 语言中的包含预定义的任何数据类型都可以被看做是空接口的实现。我们可以直接使用类型转换表达式把一个*Person类型转换成空接口类型的值,就像这样:
p := Person{"Robert", "Male", 33, "Beijing"}
v := interface{}(&p)请注意第二行。在类型字面量后跟由圆括号包裹的值(或能够代表它的变量、常量或表达式)就构成了一个类型转换表达式,意为将后者转换为前者类型的值。在这里,我们把表达式 &p 的求值结果转换成了一个空接口类型的值,并由变量 v 代表。
注意,表达式 &p( & 是取址操作符)的求值结果是一个 *Person 类型的值,即 p 的指针。
在这之后,我们就可以在 v 上应用类型断言了,即:
h, ok := v.(Animal)类型断言表达式 v.(Animal) 的求值结果可以有两个。第一个结果是被转换后的那个目标类型(这里是 Animal )的值,而第二个结果则是转换操作成功与否的标志。显然, ok 代表了一个 bool 类型的值。它也是这里判定实现关系的重要依据。
至此,我们掌握了接口类型、实现类型以及实现关系判定的重要知识和技巧。
指针
我们在前面多次提到过指针及指针类型。例如,*Person 是Person的指针类型。又例如,表达式 &p 的求值结果是 p 的指针。方法的接收者类型的不同会给方法的功能带来什么影响?该方法所属的类型又会因此发生哪些潜移默化的改变?
指针操作涉及到两个操作符—— & 和 *。这两个操作符均有多个用途。但是当它们作为地址操作符出现时,前者的作用是取址,而后者的作用是取值。更通俗地讲,当地址操作符 & 被应用到一个值上时会取出指向该值的指针值,而当地址操作符 * 被应用到一个指针值上时会取出该指针指向的那个值。它们可以被视为相反的操作。
除此之外,当 * 出现在一个类型之前(如 *Person 和 *[3]string )时就不能被看做是操作符了,而应该被视为一个符号。如此组合而成的标识符所表达的含义是作为第二部分的那个类型的指针类型。我们也可以把其中的第二部分所代表的类型称为基底类型。例如,*[3]string 是数组类型 [3]string 的指针类型,而 [3]string 是 *[3]string 的基底类型。
好了,我们现在回过头去再看结构体类型 Person 。它及其两个方法的完整声明如下:
type Person struct {
Name string
Gender string
Age uint8
Address string
}
func (person *Person) Grow() {
person.Age++
}
func (person *Person) Move(newAddress string) string {
old := person.Address
person.Address = newAddress
return old
}注意, Person 的两个方法 Grow 和 Move 的接收者类型都是 *Person,而不是 Person。只要一个方法的接收者类型是其所属类型的指针类型而不是该类型本身,那么我就可以称该方法为一个指针方法。上面的 Grow 方法和 Move 方法都是 Person 类型的指针方法。
相对的,如果一个方法的接收者类型就是其所属的类型本身,那么我们就可以把它叫做值方法。我们只要微调一下 Grow 方法的接收者类型就可以把它从指针方法变为值方法:
func (person Person) Grow() {
person.Age++
}那指针方法和值方法到底有什么区别呢?我们在保留上述修改的前提下编写如下代码:
p := Person{"Robert", "Male", 33, "Beijing"}
p.Grow()
fmt.Printf("%v\n", p)
这段代码被执行后,标准输出会打印出什么内容呢?直觉上, 34 会被打印出来,但是被打印出来的却是 33 。这是怎么回事呢? Grow 方法的功能失效了?!
解答这个问题需要引出一条定论:方法的接收者标识符所代表的是该方法当前所属的那个值的一个副本,而不是该值本身。例如,在上述代码中, Person 类型的 Grow 方法的接收者标识符 person 代表的是 p 的值的一个拷贝,而不是 p 的值。我们在调用 Grow 方法的时候, Go 语言会将 p 的值复制一份并将其作为此次调用的当前值。正因为如此, Grow 方法中的 person.Age++ 语句的执行会使这个副本的 Age 字段的值变为 34 ,而 p 的 Age 字段的值却依然是33。这就是问题所在。
只要我们把 Grow 变回指针方法就可以解决这个问题。原因是,这时的 person 代表的是 p 的值的指针的副本。指针的副本仍会指向 p 的值。另外,之所以选择表达式 person.Age 成立,是因为如果 Go 语言发现 person 是指针并且指向的那个值有 Age 字段,那么就会把该表达式视为( *person).Age 。其实,这时的 person.Age 正是 (*person).Age 的速记法。
如果一个数据类型所拥有的方法集合中包含了某一个接口类型中的所有方法声明的实现,那么就可以说这个数据类型实现了那个接口类型。要获知一个数据类型都包含哪些方法并不难。但是要注意指针方法与值方法的区别。
拥有指针方法 Grow 和 Move 的指针类型 *Person 是接口类型 Animal 的实现类型,但是它的基底类型 Person 却不是。这样的表象隐藏着另一条规则:一个指针类型拥有以它以及以它的基底类型为接收者类型的所有方法,而它的基底类型却只拥有以它本身为接收者类型的方法。
以 Person 类型为例。即使我们把 Grow 和 Move 都改为值方法,*Person 类型也仍会是 Animal 接口的实现类型。另一方面, Grow 和 Move 中只要有一个是指针方法, Person 类型就不可能是 Animal 接口的实现类型。
另外,还有一点需要大家注意,我们在基底类型的值上仍然可以调用它的指针方法。例如,若我们有一个 Person 类型的变量 bp ,则调用表达式 bp.Grow() 是合法的。这是因为,如果 Go 语言发现我们调用的 Grow 方法是 bp 的指针方法,那么它会把该调用表达式视为 (&bp).Grow() 。实际上,这时的 bp.Grow() 是 (&bp).Grow() 的速记法。
总结
本篇结束,篇幅较长,请看下一篇
(完)