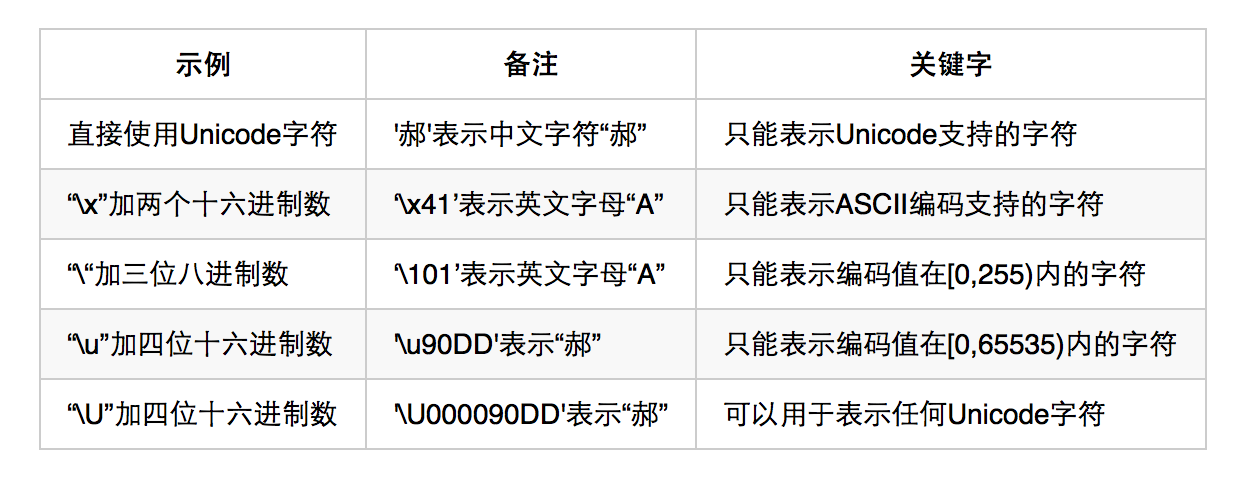
使用 Jenkins 编写 pipeline 脚本做 CI/CD。顺便分享一些我的 CI/CD 理念。
why
在没有CI/CD之前,只能手动打包、上传文件、部署到服务器,不仅部署繁琐,而且会反复产生无意义的信息和浪费资源,而且还容易造成信息差,测试人员也不确定我们部署有没有成功,我们也不确定打包后是否正常。
举个例子:
提交代码后很自信的把代码合并进去并且把源分支删除,部署上服务器后,测试人员告诉我:“这里不合格,你在优化一下“。我只能再重新从 develop 分支上 checkout 一个新分支 fix-xxx 再做一些优化,部署后,测试人员发现另外一个地方又出现问题了,打回来要重新再修改一下,如此反复,只能一遍一遍的更改,造成时间上的浪费。
下面分享一种我的 CI/CD 做法。
how
引入 git 流程规范
先看一张图,我们假定我们是按照这个 git 流程规范开发的:
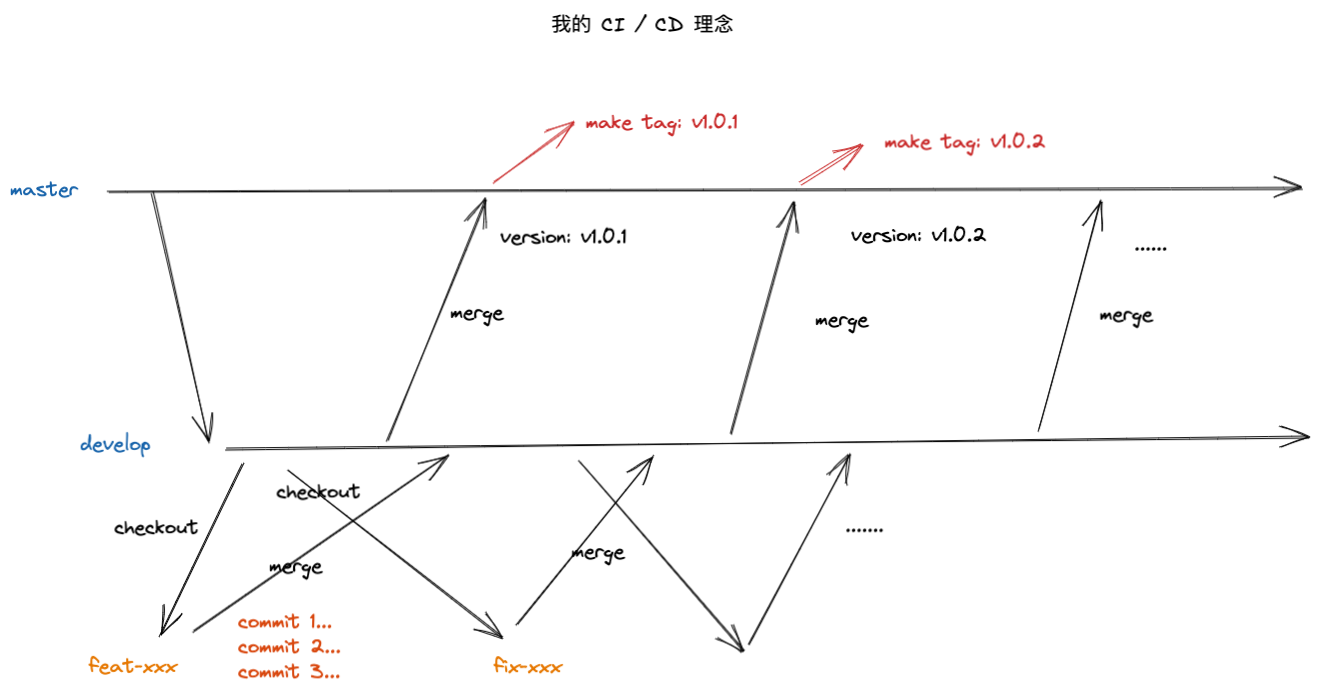
关键点:
- master 分支作为稳定分支,线上的生产环境只能来源于 master 的 tag
- develop 分支作为主开发分支,最终的目的是合并入 master 分支,所有开发者都需要基于 develop 分支 checkout 子开发分支开发代码
- 子开发分支最终的目的是并入 develop 分支
这是一个比较理想状态下的 git 流程,但是问题在于,作为开发者,你的代码必须合并到 develop 分支后才能部署,然后让测试人员测试,这样就会带来上面的问题,造成反反复复的修改。所以就又了下面这个优化后的 git 流程规范:
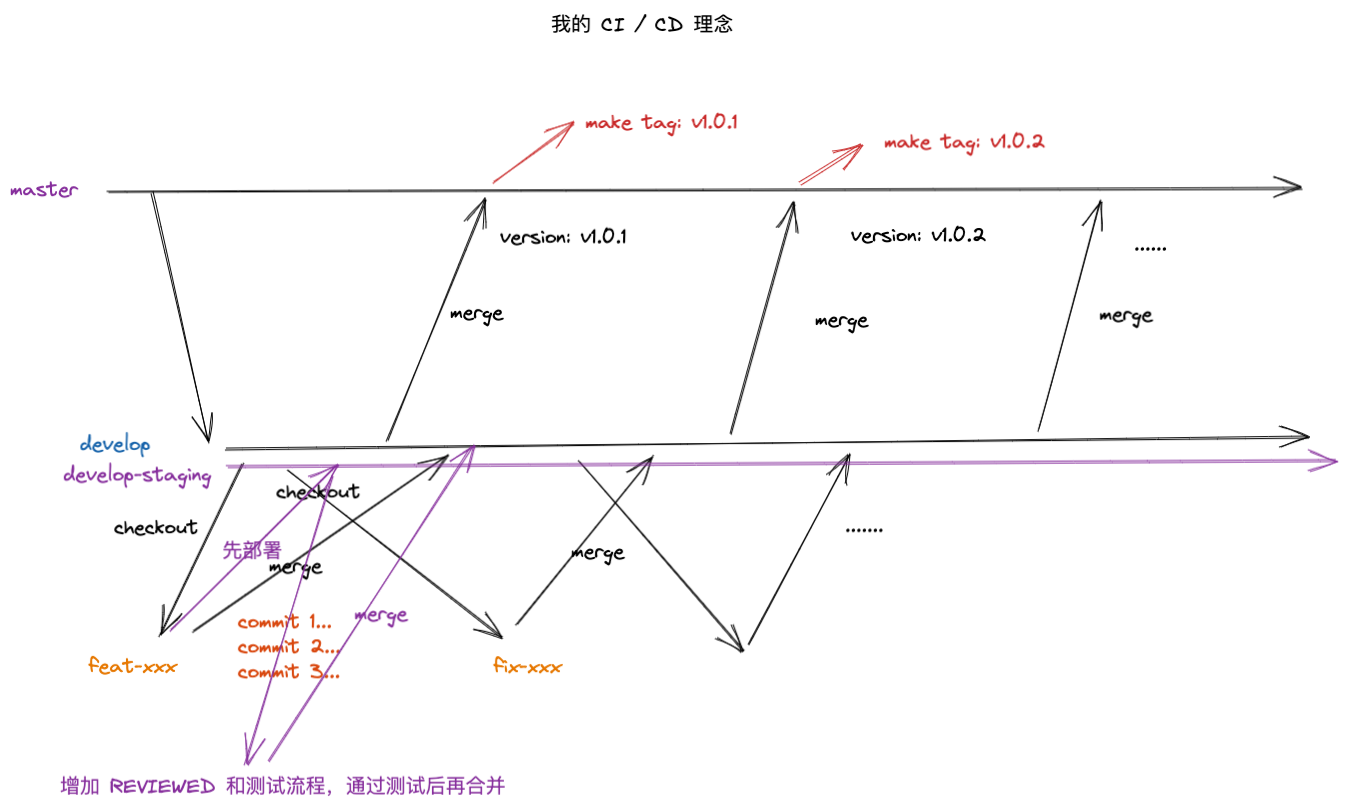
我们规定当开发者修复或者新增了某个功能,唯一合并到主开发分支的途径是通过线上发起 Merge Request,保证主干分支上的整洁。
其次我们可以充分利用 gitlib 的 label 特性,新增了一个 REVIEWED 和 PASSED_TEST 两个标签,只有当一个 Merge Request 拥有这两个标签的时候,才提醒 maintainer 该分支允许合并,且经过了测试和别人的 review。通过此方法保证主开发分支纯净以及降低主分支的缺陷概率。
那我们应该如何在多个开发者代码各自都没有合并的情况下,部署服务呢?
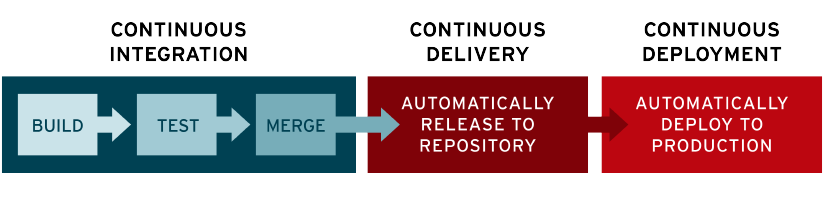
引入 Jenkins
我们可以利用 Jenkins,创建一个自动化部署的工程,对于我的项目来说,指定了以下4个参数:
Source Branch:源分支(新分支)
Target Branch: 目标分支(需要合并到哪个分支,例如 dev)
Reset Target Branch: 是否需要净化目标分支(相当于重置部署,会丢失其他已部署但未合并的分支功能)
Run npm install:是否需要安装依赖(没有引入新的依赖就不用选,增加部署速度)
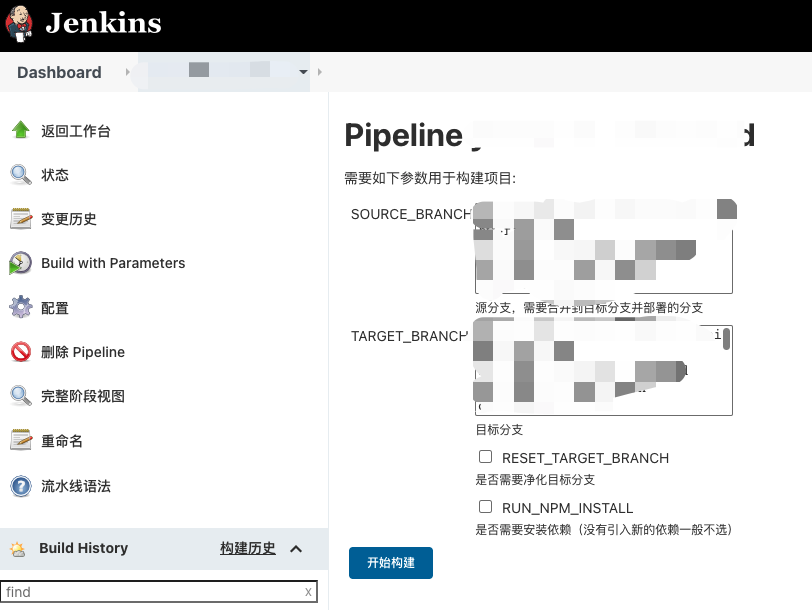
在开发者提交代码并且推送分支到 gitlib 的时候,可以依据当前实际情况选择部署方式,然后点
击开始构建按钮,整个流程就结束了,剩下的就交给服务器去构建了。
可以直接对接企业微信,通知到群消息:
下面是我的 pipeline 配置:
主要依赖以下几个插件:
- https://plugins.jenkins.io/build-user-vars-plugin/
- https://plugins.jenkins.io/http_request/
- https://plugins.jenkins.io/git-parameter/
pipeline { agent any parameters { gitParameter branch: '', branchFilter: 'origin/(.*)', defaultValue: 'develop', description: '源分支,需要合并到目标分支并部署的分支', name: 'SOURCE_BRANCH', quickFilterEnabled: false, selectedValue: 'NONE', sortMode: 'NONE', tagFilter: '*', type: 'PT_BRANCH' gitParameter branch: '', branchFilter: 'origin/(.*)', defaultValue: 'develop', description: '目标分支', name: 'TARGET_BRANCH', quickFilterEnabled: false, selectedValue: 'NONE', sortMode: 'NONE', tagFilter: '*', type: 'PT_BRANCH' booleanParam defaultValue: false, description: '是否需要净化目标分支', name: 'RESET_TARGET_BRANCH' booleanParam defaultValue: false, description: '是否需要安装依赖(没有引入新的依赖一般不选)', name: 'RUN_NPM_INSTALL' } environment { STAGING_BRANCH = 'develop-staging' // 线上的部署分支 GIT_CRED = credentials("4640b4d1-f3c2-47a6-8668-d043704444a8") // 这个是配置在全局的 git 凭据 } stages{ stage('执行开始构建企微推送通知') { steps { wrap([$class: 'BuildUser']) { script { BUILD_USER = "${env.BUILD_USER}" } } script { def start = new Date().format('yyyy-MM-dd HH:mm:ss') def head = "\"构建${JOB_NAME}:#${env.BUILD_ID}<font color=\\\"comment\\\">开始</font>,详细信息如下:" def s1 = ">源分支:<font color=\\\"comment\\\">${SOURCE_BRANCH}</font>" def s2 = ">目标分支:<font color=\\\"comment\\\">${TARGET_BRANCH}</font>" def s3 = ">是否需要净化目标分支:<font color=\\\"comment\\\">${RESET_TARGET_BRANCH}</font>" def s4 = ">是否需要安装依赖:<font color=\\\"comment\\\">${RUN_NPM_INSTALL}</font>" def s5 = ">部署时间:<font color=\\\"comment\\\">${start}</font>" def s6 = ">部署人:<font color=\\\"comment\\\">${BUILD_USER}</font>" def msg = "${head}" + "\n" + "${s1}" + "\n" + "${s2}" + "\n" + "${s3}" + "\n" + "${s4}" + "\n" + "${s5}" + "\n" + "${s6}\" " echo "${msg}" def body = "{ \"msgtype\": \"markdown\", \"markdown\": { \"content\": ${msg} } }" echo "${body}" httpRequest contentType: 'APPLICATION_JSON_UTF8', httpMode: 'POST', requestBody: "${body}", responseHandle: 'NONE', url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxxxxxxxxxxxxxx', // 企微群webhook地址 wrapAsMultipart: false } } } stage("执行初始化git") { steps { checkout([$class: 'GitSCM', branches: [[name: '${SOURCE_BRANCH}'], [name: '${TARGET_BRANCH}'], [name: '${STAGING_BRANCH}']], extensions: [], userRemoteConfigs: [[credentialsId: '4640b4d1-f3c2-47a6-8668-d043704444a8', url: 'https://xxxxxxxxxxxxxxx.git']]]) // 需要替换 git 地址 } } stage("执行处理分支关系"){ steps{ script { if (RESET_TARGET_BRANCH == 'true') { sh 'sudo git checkout ${TARGET_BRANCH}' sh 'sudo git checkout -B ${STAGING_BRANCH}' sh 'sudo git merge origin/${SOURCE_BRANCH}' } else { sh 'sudo git checkout ${STAGING_BRANCH}' sh 'sudo git merge origin/${SOURCE_BRANCH}' } } } } stage("执行安装依赖和打包") { steps { nodejs('nodejs') { script { if (RUN_NPM_INSTALL == 'true') { sh 'echo "开始安装依赖"' sh 'npm install' } else { sh 'echo "不需要安装依赖"' } sh 'npm run build' } } } } stage("执行复制打包后文件到指定目录") { steps { sh 'scp -r dist/* xxxx@192.168.7.136:/xxxxxx' // 复制文件到指定服务器指定目录 } } stage('执行构建成功企微推送通知') { steps { wrap([$class: 'BuildUser']) { script { BUILD_USER = "${env.BUILD_USER}" } } script { def start = new Date().format('yyyy-MM-dd HH:mm:ss') def head = "\"构建${JOB_NAME}:#${env.BUILD_ID}<font color=\\\"info\\\">成功</font>,详细信息如下:" def s1 = ">源分支:<font color=\\\"comment\\\">${SOURCE_BRANCH}</font>" def s2 = ">目标分支:<font color=\\\"comment\\\">${TARGET_BRANCH}</font>" def s3 = ">是否需要净化目标分支:<font color=\\\"comment\\\">${RESET_TARGET_BRANCH}</font>" def s4 = ">是否需要安装依赖:<font color=\\\"comment\\\">${RUN_NPM_INSTALL}</font>" def s5 = ">部署时间:<font color=\\\"comment\\\">${start}</font>" def s6 = ">部署人:<font color=\\\"comment\\\">${BUILD_USER}</font>" def msg = "${head}" + "\n" + "${s1}" + "\n" + "${s2}" + "\n" + "${s3}" + "\n" + "${s4}" + "\n" + "${s5}" + "\n" + "${s6}\" " echo "${msg}" def body = "{ \"msgtype\": \"markdown\", \"markdown\": { \"content\": ${msg} } }" echo "${body}" httpRequest contentType: 'APPLICATION_JSON_UTF8', httpMode: 'POST', requestBody: "${body}", responseHandle: 'NONE', url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxxxxxxxxxxxxxx', // 企微群webhook地址 wrapAsMultipart: false } } } } post { failure { echo '部署失败' wrap([$class: 'BuildUser']) { script { BUILD_USER = "${env.BUILD_USER}" } } script { def start = new Date().format('yyyy-MM-dd HH:mm:ss') def head = "\"构建${JOB_NAME}:#${env.BUILD_ID}<font color=\\\"warning\\\">失败</font>,详细信息如下:" def s1 = ">源分支:<font color=\\\"comment\\\">${SOURCE_BRANCH}</font>" def s2 = ">目标分支:<font color=\\\"comment\\\">${TARGET_BRANCH}</font>" def s3 = ">是否需要净化目标分支:<font color=\\\"comment\\\">${RESET_TARGET_BRANCH}</font>" def s4 = ">是否需要安装依赖:<font color=\\\"comment\\\">${RUN_NPM_INSTALL}</font>" def s5 = ">部署时间:<font color=\\\"comment\\\">${start}</font>" def s6 = ">部署人:<font color=\\\"comment\\\">${BUILD_USER}</font>" def msg = "${head}" + "\n" + "${s1}" + "\n" + "${s2}" + "\n" + "${s3}" + "\n" + "${s4}" + "\n" + "${s5}" + "\n" + "${s6}\" " echo "${msg}" def body = "{ \"msgtype\": \"markdown\", \"markdown\": { \"content\": ${msg} } }" echo "${body}" httpRequest contentType: 'APPLICATION_JSON_UTF8', httpMode: 'POST', requestBody: "${body}", responseHandle: 'NONE', url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxxxxxxxxxxxxxx', // 企微群webhook地址 wrapAsMultipart: false } } }}结语
Jenkins 有很多种部署方案,之前一直用的是界面化的配置,这几天刚好有时间学习了一些 pipeline 的方式,这也是我认为比较完善的一种方法。
]]>